
EHFKSWL
[Transformer] Attention is all you need 본문
Transformer에 대하여 논문을 정리해 보고자 한다. 이 논문은 2017년도에 구글에서 발표한 것으로 RNN과 CNN을 사용하지 않고 Attention 만으로 번역 task에서 당시 SOTA를 달성하였다. 지금까지도 많은 논문들이 Transformer를 기반으로 많이 나왔으며 그 분류한 표는 아래와 같다. Transformer는 자연어처리 뿐만아니라 vision 분야에서도 좋은 성능을 내고 있으므로 반드시 알아야 할 개념이라고 생각한다.

Eschewing Recurrence
Transformer와 LSTM, GRU 같은 RNN 계열 모델과의 가장 큰 차이는 Transformer가 recurrence의 특성을 제거했다는 것이다. Recurrence는 hidden state인 h_t가 h_t-1의 함수로 이루어져 있다. 그러므로 연산이 순차적으로 진행되어 학습 속도가 느려지고 메모리 문제가 발생하며, 길이가 긴 sequence에서는 학습이 잘 되지 않는 단점이 있다. 그러나 Transformer는 Attention만을 활용하여 병렬 계산이 가능하고, computation이 한번에 이루어 진다.
Encoder-Decoder
좋은 성능의 번역 모델은 encoder-decoder 구조를 가지고 있다. encdoer는 input sequence x(x1, x2, ... , xn)의 정보를 압축하여 representation인 z(z1, z2, ... zn)으로 변환하고, decoder는 z를 이용하여 원하는 도메인의 결과 sequence인 y(y1, y2, ..., yn)을 만든다. model의 모든 과정은 auto-regressive하게 이루어진다. 여기서 auto-regressive는 이전 단계에서 만든 단어를 이용하여 다음 단계의 단어를 예측하는 것을 의미한다.
Transformer도 큰 틀에서 Encoder-Decoder 구조를 가지고 있으며, self-attention, point-wise, fully connected layer만을 이용하여 구현하고 있다.
Model Architecture

Transforemr의 구조는 위와 같다. 크게 Encoder-Decoder 구조로 나누어져 있다. single attention이 아닌 Multi-head attention을 사용하고 있으며 RNN, CNN과 다르게 data의 position 값을 명시하기 위한 positional encoding과 residual connection 등의 기법이 사용되었다. 언뜻 보기에 구조가 굉장히 복잡하지만, 각 개별 block을 1개씩 살펴보면서 전체적으로 모델이 어떻게 이루어져 있는지 설명하겠다.
self-attention
먼저 Attention은 key, query, value으로 나누어 query와 key로 부터 input의 어떤 부분에 Attend 해야 하는지 결정하고 value와의 곱으로 output을 낸다. self-attention은 이 query, key, value를 input data로 부터 얻어낸다. input data X와 각 요소별 weight를 곱하면 된다. 즉 식은 다음과 같다.

Weight 들도 마찬가지로 학습된다. input word의 embedding 크기를 d_model, Q와 K의 dimension을 d_k, V의 dimension을 d_v라고 라고 하면 Q는 d_model X d_k, K는 d_model X d_k, V는 d_model X d_v 크기를 가진다. 그럼 이 self-attention을 transoformer에서는 어떻게 활용하고 있을까?
Attention in Transformer

Transformer는 여러개의 header로 이루어진 Multi Head Attention을 진행하며, 각각의 head attention은 scaled Dot-Product Attention으로 구성된다. 이 scaled Dot-product Attention은 기존에 알고 있는 attention 구조와 크게 다르지 않다. self-attention을 위해 얻은 Q, K, V를 가지고 아래와 같은 연산을 수행한다.

먼저 Q와 K의 Transpose를 곱하고 √(d_k ) 로 나누어준다. Q와 K를 곱한 값이 너무 커지면 softmax 함수의 gradient 값이 작아져 학습이 제대로 이루어지지 않을 수 있으므로 d_k로 나누어 주면서 이 효과를 상쇄한다고 한다. softmax 함수를 취한 결과의 matrix 크기는 d_model X d_model이 될 것이고 V와 곱해져 d_model X d_v의 output을 얻을 수 있다.
그리고 Multi-Head Attention은 위의 scaled-dot-product를 h번 수행한 것으로 single attention에 비하여 성능이 좋았다고 한다. 즉 h개의 query, key, value를 만들어서 서로 다른 feature를 학습하도록 만들어서 학습 효과를 높인 것이라 볼 수 있다. 이 때 Q, K, V와 Linear 부분은 각각 W_Q, W_K, W_V와 matmul 하는 것으로 Transformer에서 input으로 들어가는 Q, K, V는 모두 input data x와 같다. 이렇게 h개 만큼 나온 head들을 concat을 하고 마지막 linear layer(W_O)와 matmul 계산을 통해 최종 output을 구한다. 이 때 같은구조의 Encoder와 Decoder가 쌓여 있어(stacked) 다음 Encoder block, 혹은 Decoder block으로 값을 전달하기 때문에 Attention의 input과 output은 같은 matrix 크기를 갖는다.
Residual Connection & Layer Normalization

input data를 Multi-Head Attention에 통과시킨 후 Add와 Normalization을 진행하는 것을 위의 그림에서 볼 수 있다. 여기서 Multi-Head Attention의 input 값이 output값과 다시 Add 되는데 이를 Residual Connection 이라고 한다. 즉 input raw 값을 한번 더 학습에 참여하도록 하는 것이다. Residual connection은 학습에 다양한 이점이 있다. 다양한 상황(input data가 지나는 경로)에서 학습할 수 있다는 것이 첫번째 이다. 그리고 레이어가 많아지면 gradient가 전달되는 경로가 길어져 학습이 잘 되지 않는 현상이 발생하는데 블록을 건너 뛰므로, gradient 전달이 용이하도록 한다.

input과 output을 Add한 후 Layer normalization을 진행한다. Layer normalization은 Batch normalization과 개념은 비슷하지만 row(batch) 기준이 아닌 column(feature) 기준으로 normalization을 해준다는 차이가 있다. 쉽게 말해서 1개의 dataset 안에서 각 feature 값들에 대해 Normalization을 해주는 것이다. 위의 그림을 보면 좀 더 잘 이해할 수 있을 것이다.
Masking
Transformer architecture 그림을 보면 Decoder 구조에서 Masked Multi-Head Attention을 볼 수 있고, Multi-Head Attention 내부의 Scaled Dot-Product Attention 내부에서도 Q와 K를 곱한 후 Softmax 함수를 적용하기 전에 Masking이 optional로 들어가 있는 것을 볼 수 있다. Transformer는 2종류 masking 기법을 사용하고 있는데 각각의 역할이 다르다.
padding mask
padding mask는 직관적으로 알기 쉬운데, model이 단어 vector의 길이를 맞춰주기 위한 padding을 입력으로 취급하지 않도록 하기 위하여 masking 하는 것이다. 예를 들어 [[3, 2, 4, 0, 0],[2, 1, 0, 0, 0]] -> [[0, 0, 0, 1, 1],[0, 0, 1, 1, 1]] 과 같이 masking할 padding의 위치를 정하고 padding_mask 값이 1인 위치에 작은 음수(1e-9)와 같은 값을 더한다.
look_ahead_mask
look_ahead_mask는 Decoder의 첫번째 Multi-Head Attention block에서 사용하는 것으로 입력으로 받은 이전 단어의 값만 사용하여 다음 단어를 예측하기 위해 미래 토큰을 마스킹 하는데 사용된다. 즉 두 번째 단어를 예측하기 위해 첫 번째 단어만 사용되고, 네 번째 단어를 예측하기 위해 첫 번째, 두 번째, 세 번째 단어들이 사용 되는 것을 말한다. 예를 들어 예측하고 싶은 결과가 I love you 라면
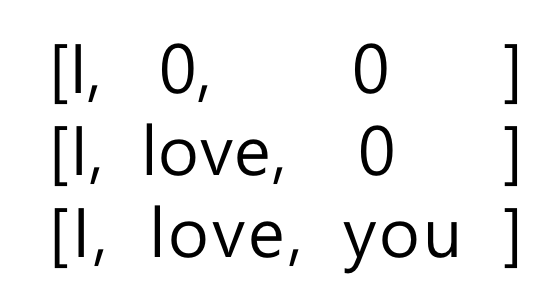
위와 같은 순서로 Decoder에 input이 들어가도록 Masking 하는 것을 말한다.
Feed-Forward
Attention Layer를 통해 값을 계산한 후 Feed-Forward Layer를 거쳐서 input과 같은 크기의 output을 최종적으로 내놓는다. Feed-Forward Layer는 2 depth로 이루어져 있으며 inner Layer는 activation function으로 relu를 취하고 있다. inner Layer의 dimension은 d_ff이고, output Layer의 dimension은 d_model(vector embedding 크기)와 같다. 즉 FFN의 계산은 다음과 같다.

Encoder Layer, Decoder Layer
이제 Encoder Layer와 Decoder Layer의 구조를 이루는 block들에 대해서는 전부 살펴보았다. 여기서 Layer를 각 단어 뒤에 붙인 이유는 Encoder와 Decoder는 이 Layer들의 N개로 구성되어 있기 때문이다. 논문에서는 6개씩 사용하고 있다고 한다.
Encoder, Decoder

바로 위에서 설명하였듯이 각 Encoder, Decoder는 각 Layer들이 나열되어 있는 구조와 같다. 또한 구조를 다시 살펴보면 Encoder의 마지막 Layer의 output이 Decoder의 입력으로 들어가는데, Encoder의 입력은 key, value와 같고 Decoder의 입력은 query와 같다. 직관적으로 생각해보면 Decoder에서 query를 던지고 Encoder에서 나온 key와 value 값으로 최종 output을 내는 구조라고 할 수 있다. 처음 이해할 때는 q, k, v 각각의 역할에 대해서 모호한 부분이 있었는데 Encoder와 Decoder로 부터의 output을 생각해보면 Transformer가 어떤 구조로 구현되어 있는지 잘 알 수 있었다.
Positinal Encoding
서두에 Positinal Encoding에 대해 언급한 것을 기억할 것이다. Transformer는 RNN, CNN과 달리 위치에 대한 정보를 모델에 넣어주지 못하므로 위치를 표현하는 vector를 input에 임의로 넣어주어 각 data의 위치를 표현해주고 있다.

저자는 positional encoding으로 sin, cos 함수를 사용하고 있다. positional encoding으로서의 이 함수의 장점은 아래와 같다. 이렇게 얻은 값과 input 값을 더하여 최종적으로 Encoding, Decoding의 input으로 넣어준다.
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
아래 자료를 참고했습니다.
https://ratsgo.github.io/nlpbook/docs/language_model/transformers/