
EHFKSWL
VAE (Variational AutoEncoder) 본문
지난 Autoencoder 글에 이어 VAE에 대한 설명글을 작성해보고자 한다. Autoencoder는 VAE를 이해하기 위한 포석 같은 것이었다. 이 VAE에는 재밌지만 어려운 개념들이 많이 나와서 VAE를 공부하면서 많은 것들을 배울 수 있었다. VAE를 구현하기 위해 공부해야 했던 많은 개념들도 포함해서 같이 작성하겠다.
주요 참고 논문
Tutorial on Variational Autoencoders
The Autoencoding Variational Autoencoder
github 주소
https://github.com/DaeseungLee/VAE-Tensorflow2.0
1. Introduction
Autoencoder에서는 Latent vector z가 원본 데이터를 최대한 잘 복원하도록 학습하여 원본 데이터를 잘 표현하는 Latent vector를 찾는 것이 주된 목적이었다. 즉 dimensinality reduction을 위한 Encoder를 만들기 위해 Decoder를 붙였다고 할 수 있다. 그러나 VAE의 목적은 이것과는 반대된다. VAE에서는 Latent vector z를 잘 찾아서 원본 데이터와 비슷한 데이터를 만들고 싶다. 즉 Decoder를 잘 만들어서 z를 통해 유사한 이미지를 만들고 싶은 것이다. 또한 이상적인 sampling z를 찾기 위하여 Encoder를 붙였기에 Autoencoder와는 반대되는 개념이라고 말한 것이다.
VAE를 완전히 이해하기 위해선 기본적인 통계 지식과 확률 개념을 알고 있어야 한다. 기본 개념들만 따로 공부하면 지루할 수 있는데 알고리즘에 어떻게 적용되는지 확인하면서 이런 기본 지식들을 공부하니 더 재밌었다.
2. Variational inference
위의 1번째 참고 논문에서 MNIST에 대한 예를 들며 Latent Variable에 대한 설명을 다음과 같이 나타내고 있다.
it helps if the model first decides which character to generate before it assigns a value to any specific pixel. This kind of decision is formally called a latent variable
위의 말에 따르면 Decoder에서 이미지를 만들어 내기 전에 만들고 싶은 숫자를 결정할 수 있다면 유용할 것이며 이런 결정 방식을 Latent variable이라고 한다. Image를 무작위로 여러 개 만드는 것이 아니라 dataset과 비슷한 이미지를 만들고 싶고, 이를 컨트롤하는 역할을 하는 것이 Latent vector이다.

Manifold Learning에서 배운 개념들을 더 사용해보면 x를 표현하는 Manifold가 존재하고, 그 Manifold 상에서의 점은 latent vecotr z이다. 그리고 그 z가 g(ϴ)라는 네트워크를 통과하면 image가 생성될 것이다. z는 생성하고자 하는 image들의 특징들을 조절할 수 있는데, 가령 사람 얼굴을 generate 한다고 했을 때 z의 각 성분은 표정이나, 성별 같은 것들을 조절할 수 있다고 한다.

VAE의 목적은 X에 대한 확률 분포 P(X)를 최대화 하는 것이라 할 수 있다. 위 식에서 z가 주어졌을 때 conditional probability는 학습을 통해 구할 수 있고, prior인 P(z)를 알고 있으므로 P(X)를 구할 수 있다. z는 이미지를 만들어 내는 controller 역할을 하므로 다루기 쉬운 확률 분포를 사용한다. 보통 Normal distribution(가우스 분포)를 사용한다.
Is it enough to model p(z) with sample distribution like normali distribution?
위와 같은 질문이 나올 수 있다. z는 X의 manifold이고 복잡할 것 같은데 z를 단순히 noraml distribution으로 간주해도 괜찮냐는 것이다. 이 질문에 대한 답은 yes이다. 왜냐면 Decoder은 DNN이기 때문에 여러 Layer가 있고 앞단의 Layer Manifold의 distribution으로 학습한다는 것이다.

그러나 위 식은 최적화 하기 어렵다. z는 무수히 많은 경우가 존재하는데 가능한 모든 z에 대해서 고려해야 하기 때문이다. 이럴 때 사용하는 방법이 변분추론(Variational Inference)이다. 위의 그림은 cs231n의 generation 강의에서 나온 slide이다.

이 부분에 굉장히 많이 헷갈렸다. 그림 (a)는 찾고싶은 data x이고 b와 c는 sampling 된 z가 decode network로부터 뽑힌 이미지이다. 단순히 이렇게 뽑아 놓고 보고 (a)와의 MSE를 계산하면 픽셀을 1만큼 옆으로 옮긴 (c)의 MSE가 (b)에 비하여 더 크게 나온다. 다시 말하면 P(X|z)의 값이 (b)에서 더 크게 나올 것이고, distribution의 평균은 (b)에 좀 더 가까워질 것이다. 의미적으로는 (c)가 (a)와 훨씬 가까움에도 불구하고 말이다.
그냥 prior로 학습을 시켜 봤더니 의미없는(망가진)이미지가 높은 확률로 많이 나오게 되는 현상이 발생한다. 그러므로 x를 잘 generate 하는 z의 이상적인 sampling 함수로 z를 sampling 해서 사용하려고 한다. 이상적인 sampling 함수를 모르기 때문에 이 함수를 추정하는 qΦ를 x를 input으로 넣어주고 학습을 통해 얻어낸다. qΦ를 계속 바꿔가면서 True posterior를 추정하고, 학습이 잘 된 경우 다시 z를 sampling하면 x값이 잘 나올 것이라고 생각한다.
이렇게 확률 분포를 구하기 어려운 경우 확률 분포를 추론하는 방법을 Variational inference라고 한다. VAE에서 V인 Variational은 위와 같은 구조 때문에 이름이 붙여졌다. 정리하면 VAE는 Decoder를 잘 만들고 싶은데 이상적인 함수에서 z를 sampling 하고 싶어 Encoder가 앞단에 붙은 구조이다. Autoencoder와 VAE는 구조가 비슷하지만 구조를 설계하는 과정에 있어 반대다.
3. Loss function
Autoencoder와 VAE는 기본적으로 구조가 같다고 했다. 구조가 같은 것은 network가 같다는 말이다. network가 같다면 무엇이 달라야 학습 결과가 달라질까? 학습되는 과정에서 둘의 차이는 Loss function이다. 먼저 VAE는 다음과 같은 2가지를 optimize 해야한다.
- Reconstruction Error
- Regularization
1번 Reconstruction Error는 Autoencoder와 마찬가지로 input과 output이 같으므로 P(x|x)의 maximize를 의미한다. 2번 Reglarization이 기존 Autoencoder의 Loss에 추가됐다고 보면 된다. 이제 Loss가 어떻게 유도되는지 한번 살펴보자.

logP_ϴ(X)로 부터 출발한다. 베이지안 룰을 적용하면서 식을 따라가다 보면 최종적으로 ELBO(Evidence LowerBOund) 와 KL divergence 2가지 term으로 유도할 수 있다. 여기서 logP_ϴ(X)는 상수로 고정되어 있다고 하면 KL divergence 값은 항상 양수이기 때문에 ELBO는 logP_ϴ(X)보다 항상 작다. 그래서 LowerBOund라는 명칭을 사용하는 것 같다. 여기서 흥미로운 점은 ELBO를 maximize 하는 qΦ를 찾으면 KL divergence를 minimize 하는 것과 같고, KL divergence를 minimize 하는 것은 qΦ가 이상적인 sampling 함수 p의 distribution과 같아진 다는 것을 의미하므로 ELBO term을 최대화하는 것만으로도 optimize 할 수 있다.

논문에 나온 문구를 그대로 가져왔다. ELBO를 Maximize 한다는 것은 Reconstruction Error의 optimize와 sampling을 추정하는 함수가 이상적인 함수에 더 가까워지는 것을 의미한다. 이것은 아래 ELBO의 수식으로 확인해 볼 수 있는데 앞의 항은 KL divergence를 나타내고 뒤의 항은 Reconstruction error이다.

위의 식을 다시 수식으로 나타내면 다음과 같다.

2가지 normal distribution의 KL divergence값은 위와 같은 수식 결과로 이미 계산되어 있다. KL divergence의 위키피디아에 유도 과정이 잘 나와있다. Reconstruction Error는 p를 bernoulli와 normal distribution 중 어느 것으로 설정하느냐에 따라서 Loss가 달라질 수 있다. bernoulli라면 cross entropy가 될 것이며, normal distribution이면 MSE가 될 것이다. Image에서는 bernoulli를 따른다고 가정하므로 Reconstruction error에 대한 log likelihood 값을 풀어쓰면 cross-entropy 가 나오게 된다.
4. Network structure
이제 Loss function을 정의했으니 Network 구조를 봐야 하는데, 그전에 위의 내용을 다시 정리해보자. Image를 generate 하기 위해 prior와 Decoder를 학습하려고 했고, Image의 distribution에 비해 prior의 분포가 단순하여 이상적인 sampling 함수를 찾기 위해 Encdoer를 붙였다. 그리고 그 이상적인 sampling 함수를 gaussian으로 approximation 하였다. 여기서 문제는 이상적인 함수를 어떻게 찾을 것인가, 즉 guassian의 mean과 variance를 어떻게 찾을지 이다.
Reparameterization Trick

Backpropagation이 가능하기 위해 Reparameterization trick이라는 방법을 사용한다. 왼쪽 그림에서는 z가 Random으로 계속 바뀌기 때문에 고정된 Parameter에서 미분이 가능하지 않는 문제가 있다. 좀 더 자세히 설명하면 같은 input에 대해서는 같은 결과가 나와야 하는데 qΦ는 Gaussian distribution의 확률 값으로 Random 하게 값을 내놓으므로 output이 계속 달라지는 것이다. 그래서 학습 시 Backpropagation이 가능하지 않다는 것이다.

그래서 Encoder에서 z값을 바로 뽑는 것이 아니라 Encoder에서 mean과 variance값을 뽑고, mean이 0이고, variance과 1인 Gaussian distribution에서 값을 하나 뽑아 variance와 곱하고, mean과 더하여 z를 만들어 낸다. 이 방법이 reparameterization trick이고, mean과 variance의 Gaussian distr ibution에서 값을 뽑는 것과 같은 결과를 보인다고 알려져 있다. 최종적으로 얻을 수 있는 z값은 아래와 같다.
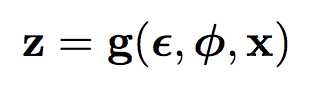
최종 구조는 다음과 같다.

5. Code
class Encoder(layers.Layer):
def __init__(self,
latent_dim=16,
intermediate_dim=64,
name='encoder'
):
super(Encoder, self).__init__(name=name)
self.h0 = Dense(intermediate_dim, activation='relu')
self.h1 = Dense(intermediate_dim, activation='relu')
self.mean = Dense(latent_dim)
self.sigma = Dense(latent_dim)
def call(self, inputs):
h0 = self.h0(inputs)
h1 = self.h1(h0)
mean = self.mean(h1)
sigma = self.sigma(h1)
z = sampling(mean, sigma)
return mean, sigma, z
class Decoder(layers.Layer):
def __init__(
self,
intermediate_dim = 64,
img_dim=784,
name='decoder'
):
super(Decoder, self).__init__(name=name)
self.h0 = Dense(intermediate_dim, activation='relu')
self.h1 = Dense(intermediate_dim, activation='relu')
self.reconstruct = Dense(img_dim, activation='sigmoid')
def call(self, inputs):
h0 = self.h0(inputs)
h1 = self.h1(h0)
reconstruct = self.reconstruct(h1)
return reconstruct
class VariationalAutoencoder(layers.Layer):
def __init__(self,
img_dim,
intermediate_dim,
latent_dim,
name='vae'
):
super(VariationalAutoencoder, self).__init__(name=name)
self.encoder=Encoder(latent_dim=latent_dim,
intermediate_dim=intermediate_dim,
)
self.decoder=Decoder(intermediate_dim=intermediate_dim,
img_dim=img_dim)
'Deep Learning > Vision' 카테고리의 다른 글
| Manifold Learning (0) | 2021.05.13 |
|---|---|
| Autoencoder (오토인코더) (0) | 2021.05.13 |

